A colleague recently asked me if we could build a chatbot to search a bunch of documents. He wanted to find past proposals where we had previously pitched services related to an upcoming project. It took literally 5-10 minutes to get a working version.
I gave ChatGPT a very basic prompt (the only 'AI knowledge' required here was the phrase "RAG implementation"): "Give me a basic RAG implementation in Python that can search across my pdf's".
After less than 30 seconds it gave me a bunch of code.
.png)
I also asked it how to run the code (in Google Colab):
.png)
And then I followed the instructions (all within Colab):
- Install the dependencies with:
!pip install "pypdf>=4.0.0" "faiss-cpu>=1.8.0" "sentence-transformers>=3.0.0" "tiktoken>=0.7.0" "openai>=1.40.0" "requests>=2.31.0" "tqdm>=4.66.0" - Use Colab's File Explorer to create
rag_pdf.pyand upload the code from before - pasting the code straight in without really reading it or making any edits might qualify this as "vibe-coding" - Use Colab's File Explorer to create a
pdfsfolder and upload some PDF files - Set an OpenAI API key with:
import os; os.environ["OPENAI_API_KEY"] = "sk-proj-xxx"(obviously use an actual API key) - Run
!python rag_pdf.py index ./pdfsto build the embeddings
And now we can run !python rag_pdf.py ask "question goes here" --top_k 5 --llm openai to answer questions using uploaded source documents.
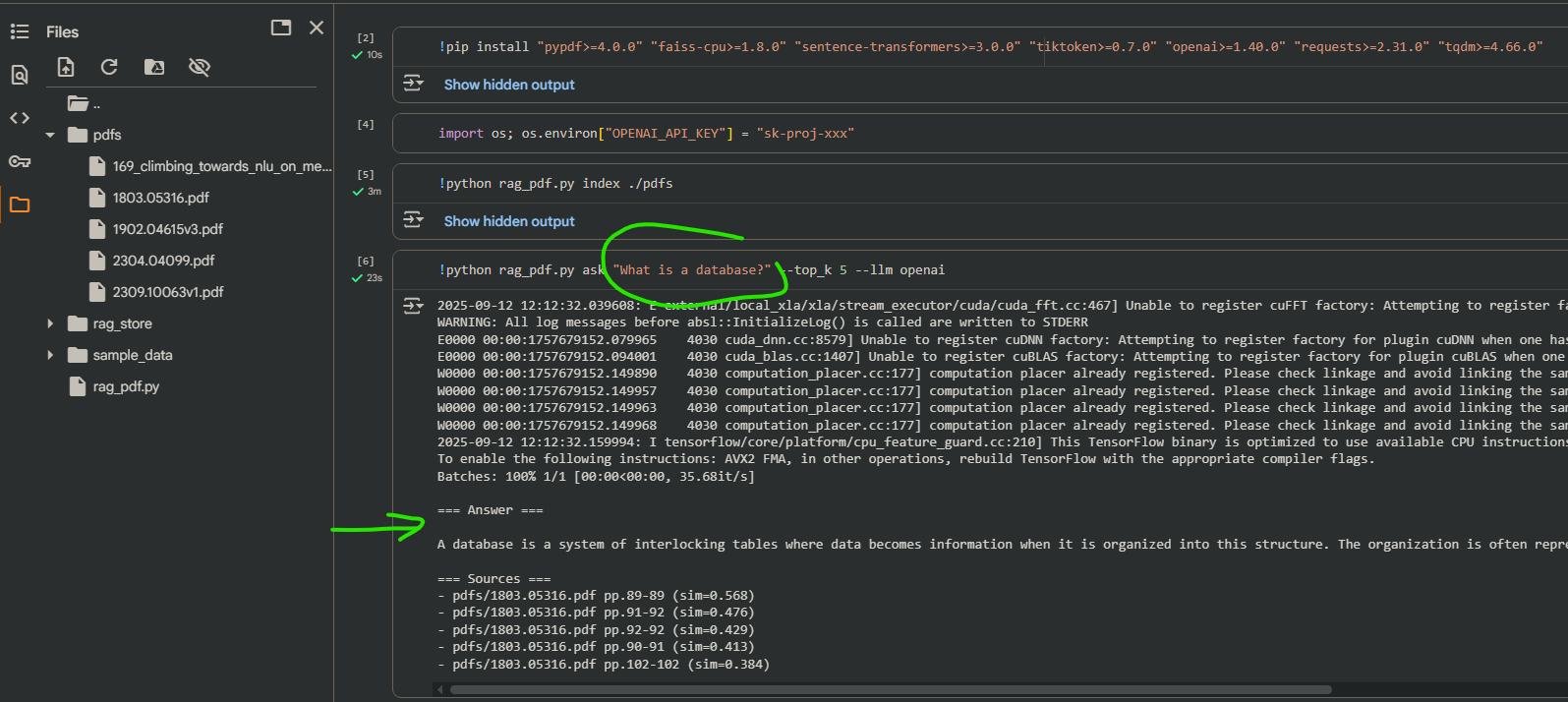
This answer indeed matches the source document on page 89 (Seven Sketches in Compositionality: An Invitation to Applied Category Theory by Brendan Fong and David I. Spivak):

Limitations¶
Obviously this is just a prototype solution. There is no clever chunking of the documents, only one type of search algorithm, no evaluation of accuracy, and out-of-the-box it only works within this ephemeral Colab environment. But it was literally faster to build an AI and start asking it questions, than it would have been to manually read through all of the PDFs.