Introduction¶
Anki is the main way that I study Chinese - I've studied for ~135 hours over the last ~400 days, generally relying on the Anki algorithm to schedule reviews from pre-built HSK decks (with my own custom tweaks to the Anki UI) - which should in theory gradually develop my skill level.
While I notice some themes (like a batch of sentences designed to introduce new vocabulary), I don't actively track what I know or where my weakness are. But inspired by Isaak Freeman hitting a vocabulary of 8000 words after 12 months I wanted to get a sense of my own progress: to baseline my current understanding against the HSK levels, and to analyse how my vocabulary is progressing over time.
Estimating vocabulary size relies on defining what "knowing" a word actually means. There are 4 different data-driven approaches we can apply to identify easy/hard words and sentences, compare the differences between modalities (reading, listening, speaking), and look at how understanding evolves over time. In doing so, we will identify tactical areas to focus on in future study sessions. Plus, it's satisfying to see a number go up.
Estimating known vocabulary size¶
Method 1 - counting non-new cards¶
Isaak simply filters his Anki collection with Hanzi:re^.{1,4}$ -is:suspended -is:new -"note:Chinese Sentences" which counts all non-new cards (excluding suspended). This is a pretty relaxed definition of "known" since it doesn't take many successful study sessions to graduate a card from the "new" state.
With a slightly stricter criterion for only including cards whose review interval has reached 7 days (roughly implying I've successfully recalled the card at least twice), I can query with "deck:Mandarin: Vocabulary" -is:new -is:suspended prop:ivl>7 to get my first vocabulary size estimate of ~1200. Of course ivl>7 is somewhat arbitrary - and later we'll look at how sensitive the size estimate is to this threshold.
Method 2 - online recognition tests¶
Another approach is to use online tests that estimate how many characters are recognised by fitting recognition probability as a function of character frequency rank (basically, given the rarity of a character, how likely are you to know it - and therefore how many characters are you likely to know in total). N Ouyang compares several methods, including:
- Eric Jiang's Hanzitest (original link defunct) - "basically works by ordering characters from most to least common and testing where you stop recognizing them".
- Hanzishan - builds on Hanzitest using Dr. Jonas Almedia's non-linear regression package for the curve-fitting and Dr. Jun Da's Modern Chinese Character Frequency List (MSTU site) for the character ordering.
I found these calculators to give lower answers (e.g. estimating a vocabulary size of 600-800 characters) - presumably because they perform quite coarse sampling (only show a few characters and at a wide range of difficulties), but possibly because they are operating on the character rather than word (= combinations of characters) level.
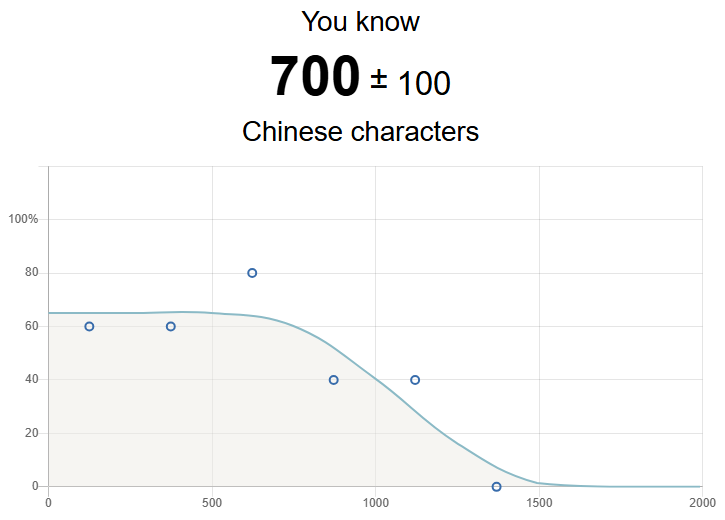 Hanzishan estimate
Hanzishan estimate
Method 3 - analysing Anki SM-2 data¶
Anki's default scheduling algorithm is SM-2 (based on SuperMemo 2). It works by assigning each card an "interval" (aka "ivl") which is the length of time until the card gets shown again - hence "spaced repetition". This interval grows with each successful review and shrinks after a failure (aka a "lapse"). If a review is marked Easy or Hard then its inherent "Ease Factor" (aka "factor") is adjusted up or down respectively - and this is used to modify the interval delta (i.e. cards with higher ease have their interval grow more quickly).
The question is: how do we use these statistics to find easy (or hard) cards? Is it possible to apply a threshold like factor > y?
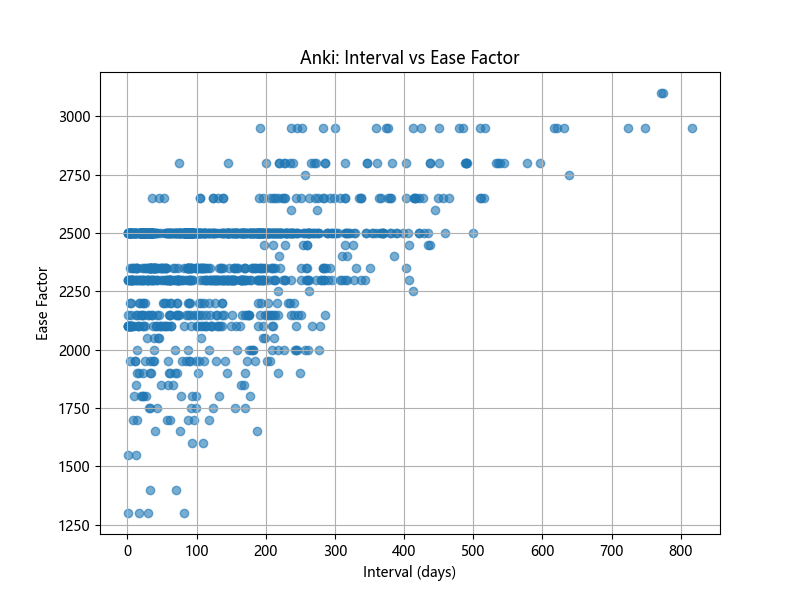
When examining the distributions of ivl and factor, we can notice that ivl steadily grows as reviews succeed and shrinks after lapses - so it's a decent indicator of how well-learned a card is. By contrast, factor changes only on "Hard" or "Easy" reviews (most reviews are "Good" which leaves factor unmodified) - so it offers less as a predictor of true memory ability because the data isn't hugely smooth or reliable.
Unfortunately, ivl has a trade-off: because is updated more frequently for each card, it becomes a more continuous distribution and it's unclear where to set a cut-off threshold x if we want to estimate vocabulary size as |{cards : ivl > x}|. Do we define a card as "known" if Anki thinks we don't need to review it until 7 days have passed? Or a month? Or 100 days? Our vocabulary size will flex depending on where we set the threshold value.
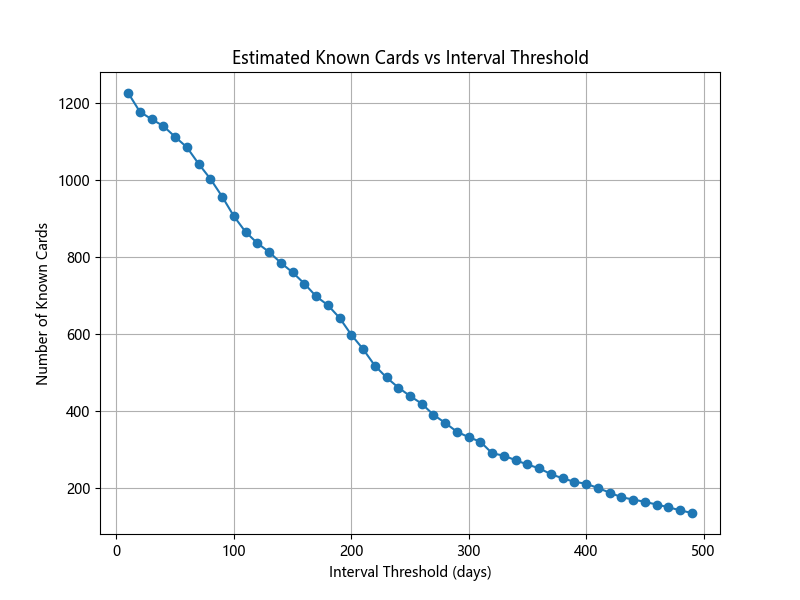
In addition, we might be missing new cards whose interval hasn't had a chance to grow but where the new word is already pretty easy (and could therefore be considered "known" after just a few reviews). Ease factor should provided some indication of these words, so we don't want to completely lose that signal.
The more robust approach would be to explore the ivl-factor space and test cards at different threshold points to determine the region of "true" memorisation:
nearby_cards = df[
(df["ivl"].between(target_ivl - delta_ivl, target_ivl + delta_ivl)) &
(df["factor"].between(target_factor - delta_factor, target_factor + delta_factor))
]
.png)
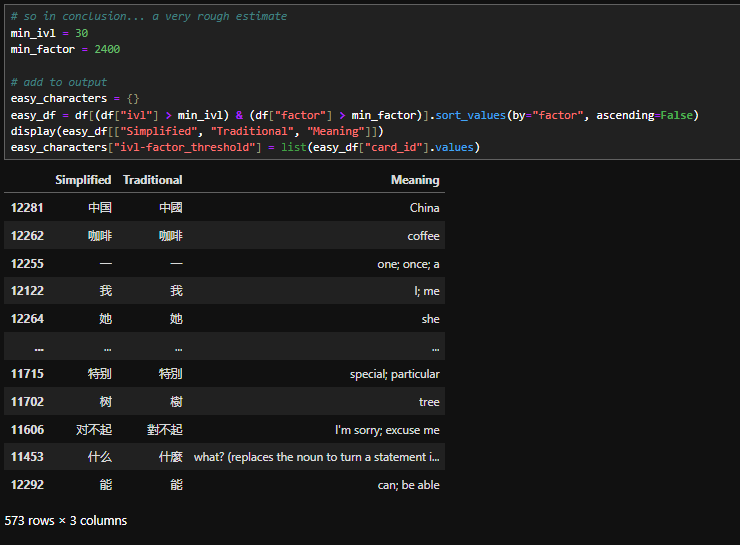
But without getting in to all this nuance... a pragmatic compromise is to set a joint ivl-factor threshold and filter. This definitely shows easy words (中国, 咖啡, etc) but the cut-off point is fairly arbitrary. This example gives me an estimated vocabulary of ~600 (which is likely under-counting by ignoring known cards with average factor scores).
Method 4 - analysing Anki FSRS data¶
Retrievability¶
Anki has an alternative algorithm - FSRS - which models memory decay to predict review intervals such that recall probability is kept near a target level (default 90%). Helpfully for us, one of the internal model variables is Retrievability, defined as "the probability that the person can successfully recall a particular information at a given moment". This sounds like a much closer proxy for defining "known" and estimating vocabulary size!
Unfortunately, Retrievability is very skewed towards 1 (possibly due to my FSRS parameters, or maybe I'm just good at remembering things!) so doesn't give as much signal as hoped.
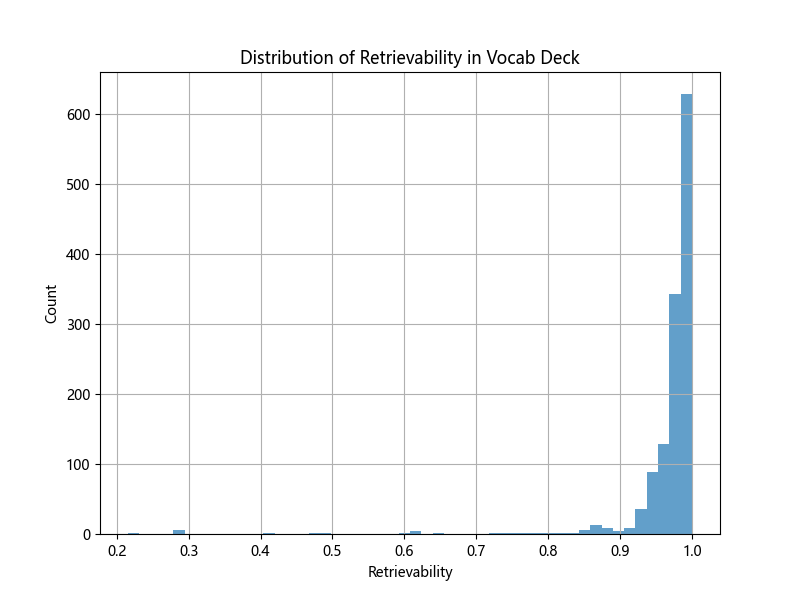
We also get the same threshold definition problem (i.e. where do we set the cut-off?).
.png)
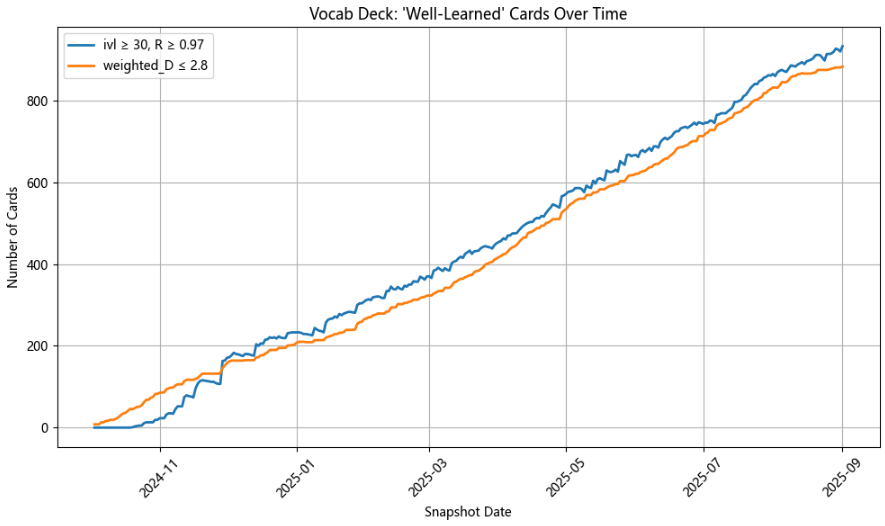
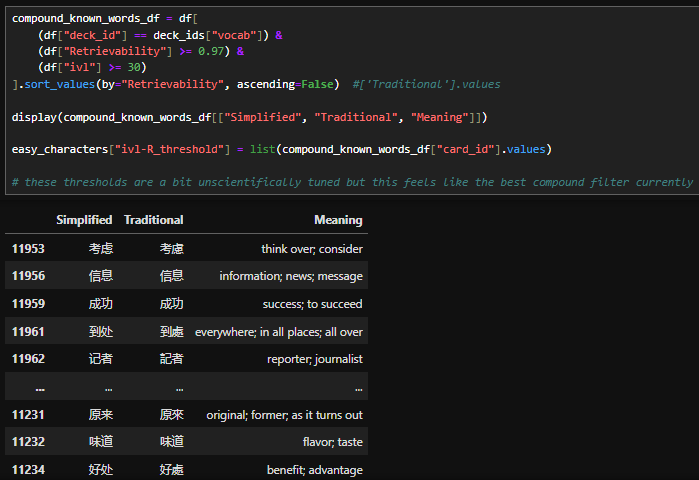
Another immediate observation is that Retrievability seems to be the most forgiving metric (it creates higher estimates than the other methods) so the best way to use it is to set a high threshold (e.g. R>=0.97) and combine it with ivl to mitigate a major issue which is that cards with recent successful reviews will have a high Retrievability. The results look valid but due to this recency bias will include cards which do not necessarily feel the absolute easiest, and fluctuate depending on data snapshot time (as can be seen from the differing results below).
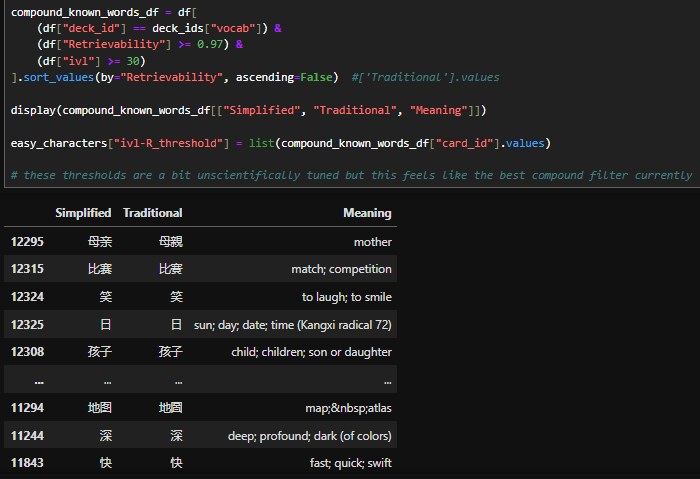
Difficulty & Stability¶
Other FSRS statistics (Difficulty and Stability) provide a less time-dependent score for each card. Difficulty is similar to SM-2 Ease Factor - it relates how quickly or slowly the scheduling interval of an individual card should change (this is a somewhat handwavy explanation because FSRS is a bit of a black box); while Stability is the time taken for Retrievability to drop from 100% to 90%.
Stability is sort of like FSRS's equivalent to SM-2's ivl, in that it gives a time estimate related to memory, and has a similarly shaped distribution. Also like ivl, Stability grows each time you successfully review a card, Ease Factor which only changes on “Hard/Easy” responses. But "taking more than X days for R to drop from 100% to 90%" is not necessarily a good way to define "known".
The most useful way which I found to use these metrics is to combine them into a "Stability-weighted Difficulty" score where the temporal aspect of Stability creates a richer, more longitudinal view of memory:
- a card with high Stability has passed multiple reviews - demonstrating that it is "known"
- whereas a card with low Stability might look easy (e.g. high current Retrievability) but only due to recency of review
so we use Stability to contextualise Difficulty:
- Stability tells you how settled a memory is: how long it’s expected to last given its history.
- some cards have a high Difficulty not because they’re conceptually hard, but because they’re still early in their review lifecycle and haven't 'settled'
- therefore, a high Difficulty among stable cards suggests genuine difficulty, whereas a low Difficulty among stable cards implies a truly "known" card
This motivates a combined metric which is correlated with Difficulty and inversely correlated with Stability. I played around with formulas until I got a metric that correlated with Difficulty while also showing enough variation when varying Stability across a band of fixed Difficulty:
df["Stability_days_norm"] = (df["Stability_days"] - df["Stability_days"].min() + 1000)/(df["Stability_days"].max() - df["Stability_days"].min())
df["weighted_D"] = (1+df["Difficulty"])**0.5 / (df["Stability_days_norm"])**0.3
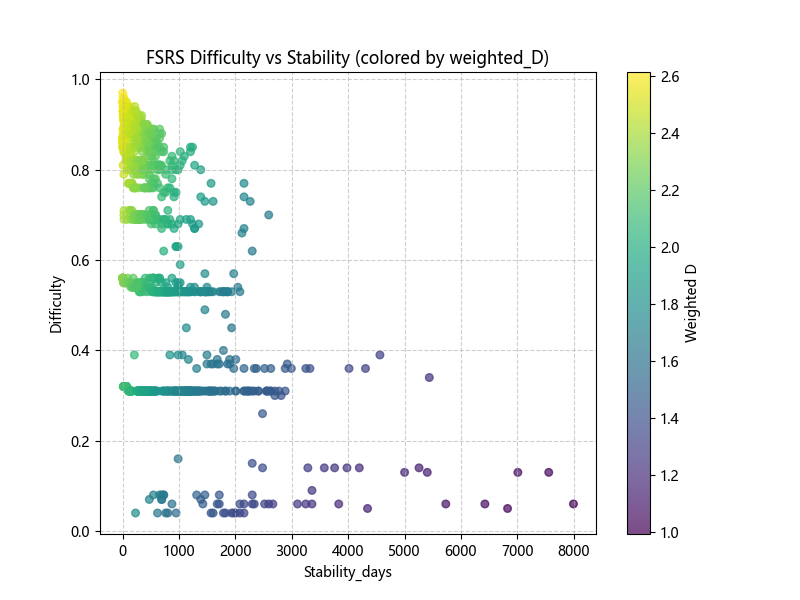
Empirically, this method does return genuinely "known" words.
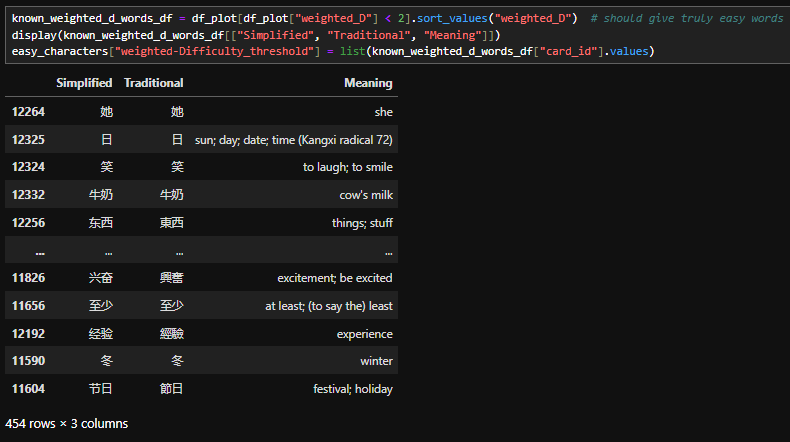
From both SM-2 and FSRS Anki data analysis, we now have a set of methods which taken together estimate a vocabulary size of ~1000.
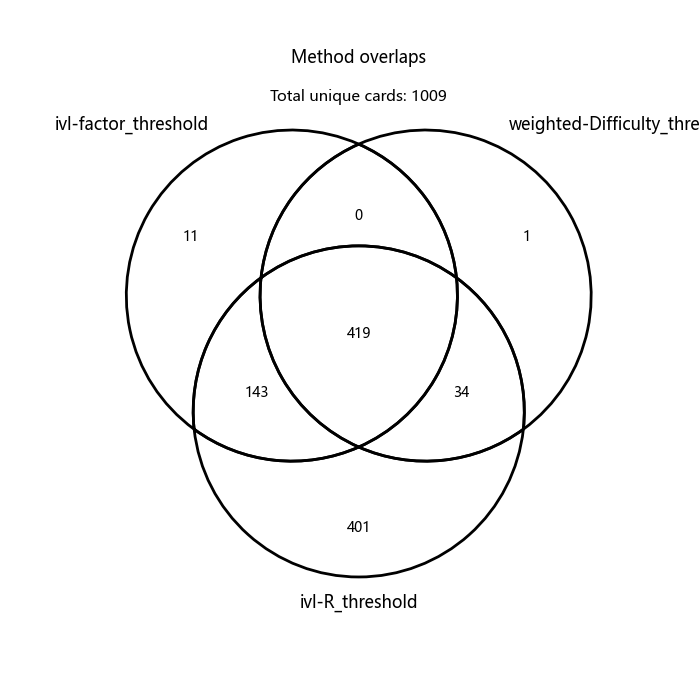
It's promising that the methods have a strong overlap, as it implies that none majorly incorrect or poorly tuned. The ivl-R method clearly does most of the work and picks up cards missed by the other methods; and after inspecting the results this seems justified - they are cards with high ivl but lower factor or higher D, implying that they have been reviewed consistently over time but I haven't marked them as "Easy" very often.
Filtering for difficult cards¶
Having estimated what's easy, the natural next question is "what's hard?". Now that we have a set of working filters, we can adjust the thresholds and invert them to find difficult cards instead of easy ones, for extra reviews and study sessions.
I used the same filters but added an extra one looking for cards which had received the most lapses (i.e. failed reviews) but only counting lapses which occurred more than 2 days after the card was started.
At the time of writing, my most difficult characters (based on Retrievability - which could mean they are difficult because they haven't been reviewed in a while) are:
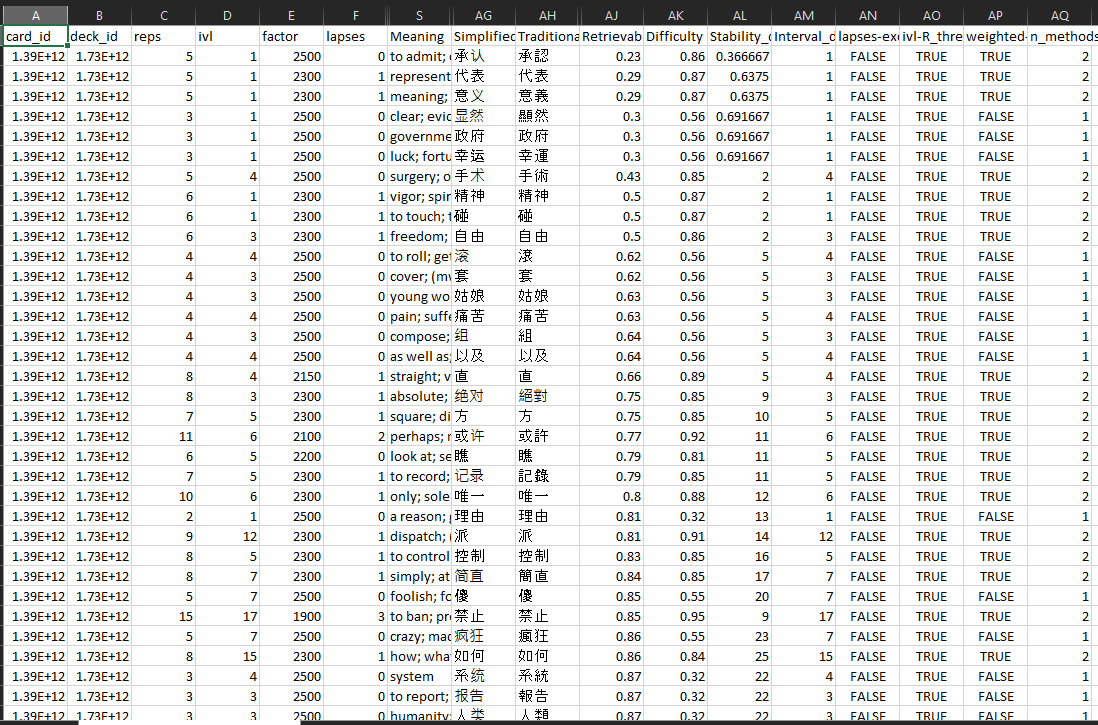
while the most inherently difficult characters, more robust against recency bias (as can anecdotally be seen from the lapses column), are:
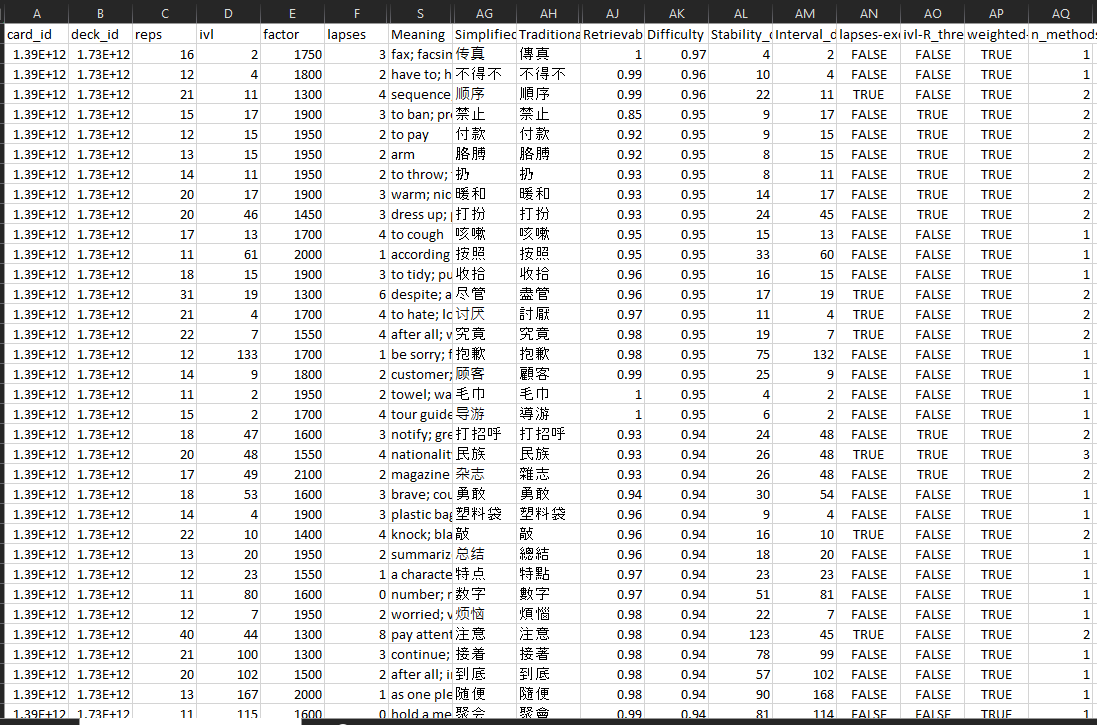
Looks like 注意 and 尽管 are really tough words for me to remember!
I also computed the time series of historic statistics for all cards based on the logged review data to create the animation below. It's clear that there is a 'breeze' of forgetting which constantly pushes cards down the Retrievability axis, especially the small subset of particularly difficult ones (high weighted difficulty, low interval). We can also see cards decreasing their weighted difficulty in 'bands' as their intervals grow, presumably related to how many times they have received "Easy"/"Hard" reviews.

Comparing modalities¶
I applied similar analysis to my sentence decks. I use the same deck but adjust the template so that it functions to practice reading (show Chinese text), listening (play audio) and speaking (show English text). It's interesting to look at how card statistics differ across these modalities.
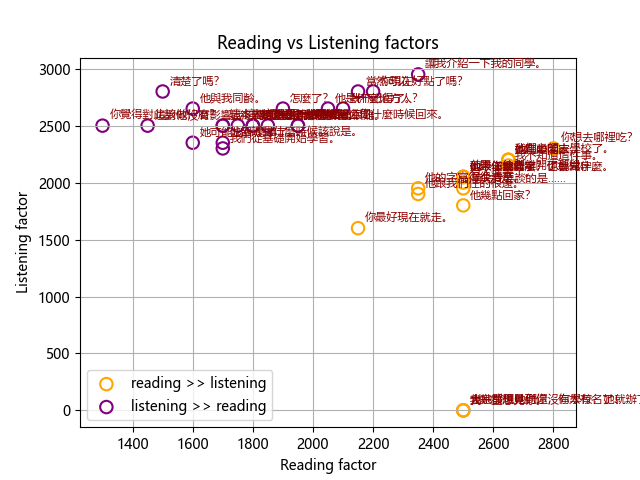
Some initial observations from these results include:
Easier when reading vs listening:
- 你最好現在就走。- I would guess that sentences with words which are visually but not sonically distinctive (e.g. 走 (zǒu) vs 做 (zuò)) are easier to read. It also shows I need to do more tone practice...
- 首先我要談的是…… - this is an unfinished sentence which is indicated visually but not sonically.
- 他跟你說什麼,你就做什麼。- the grammar in this sentence is easy to see visually.
Easier when listening vs reading:
- 我了解她。- seeing 了 written down (as part of 了解 rather than to indicate changed state or 'past tense') might be confusing.
- 這本書誰想要就給誰吧。- this grammar is quite difficult to read.
- 他是什麼地方人?- the audio file for this card has a very distinctive sound.
- 讓我介紹一下我的同學。- learning the phrase "介紹一下" was tricky in the reading deck, but it is a very distinctive phrase to hear.
This analysis makes me want to analyse cards not just based on Anki statistics, but on the inherent attributes of words and phrases. It might be that the presence of multiple characters like 笑 (xiào), 写 (xiě), 下 (xià) in a sentence imply it would be more difficult to hear, for example. At some point I will train an ML model to predict inherent difficulty based on character n-grams, plus other features like pinyin, sentence length and constituent radicals (since it's sometimes possible to deduce the meaning of a previously unseen word from its pictographic semantic radicals).
Using the results¶
One thing that I've already learned from this process is that I should be less strict on when to press the "Easy" button in order to get smoother factor distribution and better discern easy cards.
I'm able to get a regular update of new words and phrases which are just on the border of my understanding, or to track what I've been learning recently. If in future I combine this with richer card tagging, then I should be able to find high level themes such as grammatical structures that need more work (/u/BetterPossible8226 regularly posts structures and devices on /r/ChineseLanguage; of course there are also other great online sources). I should also be able to use this foundation to track granular progress, like whether previously difficult cards are becoming easier over time, and how quickly. Asking ChatGPT to summarise key themes of some borderline difficulty sentences brought out the following focus areas:
- 把 / 被 / passive–active manipulation (e.g. 把地图展开, 房子被吹倒了): You’re working on controlling verb directionality and focus — a typical HSK3–4 hurdle.
- “在…中” structure for abstract contexts (e.g. 在这次比赛中, 在同一个世界, 在街边派发资料): Practicing “context-setting” clauses — very natural in writing or formal speech.
- Modal verbs & adverbs of degree / attitude (e.g. 不能指望, 似乎, 几乎, 偶然, 临时, 曾, 已经): You’re exploring shades of certainty and time, which can be tricky to master.
- Complex connectors (e.g. 因为...所以..., 经过..., 虽然...但是... (implied), 所认识的…): Indicates growing comfort with multi-clause sentences.
- “得” constructions (complement of degree) (e.g. 竞争得很激烈, 弄得她不自在了): Suggests focus on nuance — describing how something happens.
- Resultative and directional complements (e.g. 弄得…, 走开, 拿出来): Subtle and context-dependent.
- Nuanced emotion or attitude words — distinguishing between, e.g., 吃惊 vs 惊讶, 偶然 vs 临时.
- Abstract or metaphorical subjects — sentences like 科技可以推动经济发展 or 他们之间斗争了好多年 indicate a shift toward non-concrete nouns and relationships.
- Register control — mixing formal (政府官员, 出台政策) with colloquial (妈的!真不错!) suggests you’re exploring tone and appropriateness.
I can also use this data to create personalised LLM prompts for language learning sessions. I used the analysis results to mock up a simple prompt with elements such as:
Student's Level
- HSK2 level: The student has a solid foundation in basic vocabulary, sentence structures, and conversational skills.
- Can construct simple and slightly complex sentences accurately.
- Understands key grammar patterns like "因为...所以..." and comparative structures like "比".
- Able to express preferences and reasons (e.g., "我喜欢吃米饭因为很好吃").
Vocabulary:
The student has a reasonable beginner vocabulary, including:
- **Basic Nouns**: 水果, 朋友, 米饭, 西瓜, 学校, 教室, 父母, 动物 (e.g., 狗, 猫).
- **Verbs**: 吃, 喝, 喜欢, 明白, 工作, 学习, 帮助, 跑步, 起床, 睡觉, 读书.
- **Adjectives**: 好吃, 可爱, 漂亮, 简单, 便宜, 热, 冷.
- **Key Grammar Words**: 很, 不, 了, 的, 吗, 和, 因为, 所以, 如果.
- **Quantifiers**: 一, 二, 百, 千, 半.
- **Time Expressions**: 今天, 明天, 现在, 小时, 分, 中午.
Useful code¶
To load in Anki collection data and merge in FSRS data (see below):
import sqlite3
import pandas as pd
from matplotlib import rcParams
from datetime import datetime, timedelta
def get_timestamp() -> str:
return datetime.now().strftime("%Y-%m-%d-%H%M%S")
timestamp = get_timestamp()
rcParams['font.sans-serif'] = ['Microsoft YaHei'] # needed for adding Chinese to matplotlib charts
pd.set_option("display.max_columns", 100)
ANKI_COLLECTION_INFILE = r"collections/collection-20251014143643/collection.anki21"
MAPPING_CSV = r"anki_Spoonfed_crossdeck_mapping.csv"
CREATE_OUTPUT_CSVs = True
# Deck IDs of interest
deck_ids = {
"reading": 1727892404417, # Spoonfed Chinese
"listening": 1742915410699, # Spoonfed Chinese [Listening]
"speaking": 1748000867369, # Spoonfed Chinese [Speaking]
"vocab": 1727904089773 # Mandarin: Vocabulary::a. HSK
}
deck_id_tuple = tuple(deck_ids.values())
deck_id_to_name = {deck_ids[n]: n for n in deck_ids.keys()}
# Get cards from collection
conn = sqlite3.connect(ANKI_COLLECTION_INFILE)
cards_df = pd.read_sql_query(f"""
SELECT
cards.id AS card_id,
cards.did AS deck_id,
cards.reps,
cards.ivl,
cards.factor,
cards.lapses,
cards.due,
notes.flds,
notes.mid AS model_id
FROM cards
JOIN notes ON cards.nid = notes.id
WHERE cards.did IN {deck_id_tuple}
""", conn)
# --- Load model schemas ---
cursor = conn.cursor()
cursor.execute("SELECT models FROM col LIMIT 1")
models_json = cursor.fetchone()[0]
models = json.loads(models_json)
conn.close()
# Map model_id -> list of field names (ordered)
model_fields = {int(mid): [f['name'] for f in m['flds']] for mid, m in models.items()}
# --- Expand fields dynamically ---
def expand_fields(row):
fields = row['flds'].split('\x1f') if pd.notna(row['flds']) else []
model_id = row['model_id']
names = model_fields.get(model_id, [])
data = {}
for i, name in enumerate(names):
data[name] = fields[i] if i < len(fields) else None
return pd.Series(data)
expanded_df = cards_df.join(cards_df.apply(expand_fields, axis=1))
expanded_df.head()
fsrs_data = pd.read_csv(r"browse_export (1).csv") # run Anki add-on with columns: Sort Field, Card Type, Due, Deck, Retrievability, Difficulty, Ease, Interval, Answer, Stability
# and search filter `(deck:Mandarin* OR deck:Spoon*) -is:new`
# then select all cards and do Edit > Export Visible
import unicodedata
def to_days(value: str) -> float:
if value == "(learning)": # handle edge case
return 0
try:
# Normalize to strip weird unicode characters
text = unicodedata.normalize("NFKC", str(value)).lower()
# Remove any non-breaking spaces or invisible chars
text = re.sub(r"[^\x00-\x7F]+", " ", text).strip()
match = re.match(r'^([\d\.]+)\s*(hour|hours|day|days|month|months|year|years)$', text)
if not match:
return "ERROR"
num = float(match.group(1))
unit = match.group(2)
if "day" in unit:
return num
elif "month" in unit:
return num * 30
elif "year" in unit:
return num * 365
elif "hour" in unit:
return num / 24
else:
return "ERROR"
except:
return "ERROR"
# convert raw data (strings) into days
for col in ["Stability", "Interval"]:
fsrs_data[f"{col}_days"] = fsrs_data[col].apply(to_days)
assert len(fsrs_data[fsrs_data[f"{col}_days"] == "ERROR"]) == 0
# let's also convert R, D into % (Float)
for col in ["Retrievability", "Difficulty"]:
fsrs_data[col] = fsrs_data[col].apply(lambda x: float(x.replace("%",""))/100)
# merge onto expanded_df
expanded_df = expanded_df.merge(fsrs_data[["card_id", "Retrievability", "Difficulty", "Stability_days", "Interval_days"]], on="card_id", how="left") # Interval_days is just for dataset comparison
I naively assumed that the FSRS stats would appear as new columns in my anki.21 card table when switching from SM-2 to FSRS. Initially I used py-fsrs to re-implement the FSRS algorithm after first getting the revlog with fsrs_optimizer. But it turns out you can access both the revlog and the FSRS stats quite easily within the Anki app using an Anki Desktop add-on (just add this code to AppData\Roaming\Anki2\addons21\my-addon\__init__.py).
If you do want to re-implement the FSRS algorithm for whatever reason then you can do it by first getting the revlog data:
# 1. Get the revlog data - see https://colab.research.google.com/github/open-spaced-repetition/fsrs4anki/blob/v6.1.3/fsrs4anki_optimizer.ipynb
# see the above Colab for more details on params
filename = "collection-2025-09-26@17-14-15.colpkg"
timezone = 'Europe/London'
next_day_starts_at = 4
revlog_start_date = "2006-10-05" # YYYY-MM-DD
filter_out_suspended_cards = False
filter_out_flags = []
enable_short_term = True
recency_weight = True
%pip install -q fsrs_optimizer==6.1.5
import fsrs_optimizer as optimizer
optimizer = optimizer.Optimizer(enable_short_term=enable_short_term)
optimizer.anki_extract(filename, filter_out_suspended_cards, filter_out_flags)
analysis = optimizer.create_time_series(timezone, revlog_start_date, next_day_starts_at)
# revlog.csv saved.
Then simulate reviews with the FSRS scheduler:
# 2. Simulate card reviews to derive FSRS statistics
%pip install fsrs
import csv
from datetime import datetime, timezone
from fsrs import Card, ReviewLog, Rating, Scheduler, Optimizer
from tqdm import tqdm
# Map your CSV rating to fsrs.Rating
RATING_MAP = {
1: Rating.Again,
2: Rating.Hard,
3: Rating.Good,
4: Rating.Easy
}
review_logs = []
with open("revlog.csv", newline="") as f: # built using fsrs-optimizer step above
reader = csv.DictReader(f)
for row in reader:
# Convert CSV fields
card_id = int(row["card_id"])
review_time = datetime.fromtimestamp(int(row["review_time"]) / 1000, tz=timezone.utc)
review_rating = RATING_MAP.get(int(row["review_rating"]))
review_duration = int(row["review_duration"]) if row["review_duration"] else None
# Build ReviewLog using from_dict
rl_dict = {
"card_id": card_id,
"rating": review_rating,
"review_datetime": str(review_time),
"review_duration": review_duration
}
review_log = ReviewLog.from_dict(rl_dict)
review_logs.append(review_log)
# fix timestamps
for rl in review_logs:
rl.review_datetime = rl.review_datetime.replace(tzinfo=timezone.utc)
print(f"Loaded {len(review_logs)} review logs.")
### Start reviewing
now = datetime.now(timezone.utc) # set time for calculating current retrievability
# FSRS weights can be accessed from the deck presets menu in Anki
weights = [0.4783, 1.2172, 9.7398, 15.8796, 6.8942, 0.3659, 3.2729, 0.0099, 1.4107, 0.0061, 0.5899, 1.68, 0.009, 0.4049, 1.2676, 0.0, 3.0064, 0.3535, 0.5764, 0.2246, 0.2205]
scheduler = Scheduler(parameters=weights)
cards_state = {}
# Review all cards
for rl in tqdm(sorted(review_logs, key=lambda x: x.review_datetime)):
card = cards_state.get(rl.card_id, Card())
card, _ = scheduler.review_card(card, rating=rl.rating, review_datetime=rl.review_datetime, review_duration=rl.review_duration)
cards_state[rl.card_id] = card
# Sanity check results - we should see R < 1.0
for ckey in tqdm(list(cards_state.keys())):
if scheduler.get_card_retrievability(cards_state[ckey], current_datetime=now) < 1:
print(f"\nFound an R less than 1.0: {ckey}")
break
### Get statistics
# This is how to access the statistics
print(
scheduler.get_card_retrievability(cards_state[ckey], current_datetime=now),
cards_state[ckey].stability,
cards_state[ckey].difficulty
)
# or at a future date
from datetime import timedelta
c = cards_state[ckey]
scheduler.get_card_retrievability(c, current_datetime=c.last_review + timedelta(days=5)) # simulate a future R score
# Difficulties need to be normalised for Anki convention of displaying as %
# Extract all raw difficulties, expected to fall within [1,10] as per https://github.com/open-spaced-repetition/fsrs4anki/wiki/The-Algorithm#symbol
all_difficulties = [card.difficulty for card in cards_state.values()]
# Define min/max for scaling
min_diff = 1
max_diff = 10
def to_anki_percent(difficulty, min_diff=min_diff, max_diff=max_diff):
"""Map raw FSRS difficulty to 0–100% scale like Anki."""
pct = (difficulty - min_diff) / (max_diff - min_diff) * 100
return max(0, min(100, pct)) # clamp to 0–100
# compute percentages for all cards
difficulty_percent = {cid: to_anki_percent(card.difficulty)
for cid, card in cards_state.items()}